
Projects
Public Health
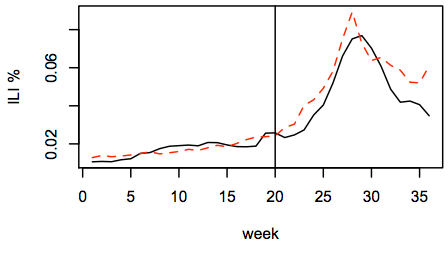 The proliferation of social media – such as Twitter, Facebook, blogs, and Web forums – has created an unprecedented, continuous stream of messages containing the thoughts, opinions, and beliefs of millions of people. Can we transform this raw data into insights about public health? Our recent work has shown promising results mining online data to monitor disease symptoms and estimate population health, suggesting that this new data source can enhance our understanding of the relationships among health, behavior, personality, and environment.
The proliferation of social media – such as Twitter, Facebook, blogs, and Web forums – has created an unprecedented, continuous stream of messages containing the thoughts, opinions, and beliefs of millions of people. Can we transform this raw data into insights about public health? Our recent work has shown promising results mining online data to monitor disease symptoms and estimate population health, suggesting that this new data source can enhance our understanding of the relationships among health, behavior, personality, and environment.
Publications
- Discovering and Controlling for Latent Confounds in Text Classification Using Adversarial Domain Adaptation, SDM 2019
- Forecasting the presence and intensity of hostility on Instagram using linguistic and social features, ICWSM 2018
- Robust Text Classification under Confounding Shift, JAIR 2018
- Learning from noisy label proportions for classifying online social data, SNAM 2018
- Mining the Demographics of Political Sentiment from Twitter Using Learning from Label Proportions, ICDM 2017
- Co-training for Demographic Classification Using Deep Learning from Label Proportions, ICDM 2017
- Controlling for Unobserved Confounds in Classification Using Correlational Constraints, ICWSM 2017
- Identifying leading indicators of product recalls from online reviews using positive unlabeled learning and domain adaptation, ICWSM 2017
- Robust Text Classification in the Presence of Confounding Bias, AAAI 2016
- Reducing confounding bias in observational studies that use text classification, OSSM 2016
- A demographic and sentiment analysis of e-cigarette messages on Twitter, CHS 2015
- Using Matched Samples to Estimate the Effects of Exercise on Mental Health from Twitter, AAAI 2015
- Reducing Sampling Bias in Social Media Data for County Health Inference, JSM Proceedings
- Estimating County Health Statistics with Twitter, CHI 2014
- Lightweight methods to estimate influenza rates and alcohol sales volume from Twitter messages, Language Resources and Evaluation, 2013
- Detecting influenza epidemics by analyzing Twitter messages, arXiv:1007.4747v1 2010
- Towards detecting influenza epidemics by analyzing Twitter messages, KDD 2010 Workshop
Crisis Informatics
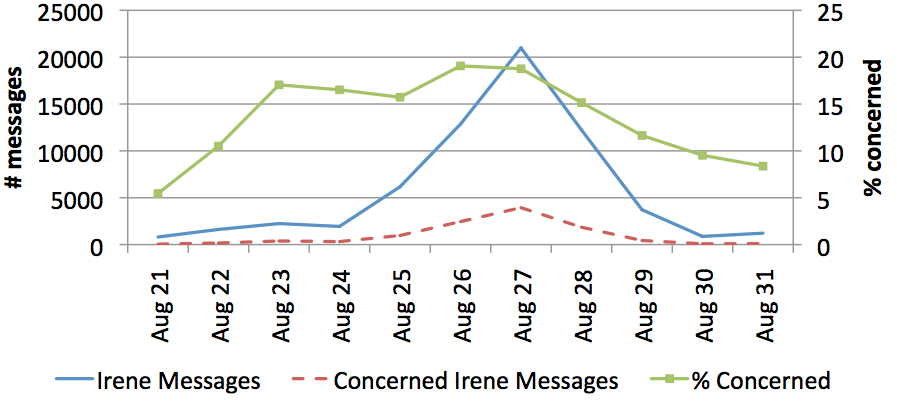 During disasters such as hurricanes, first-responders need situational awareness to make the right decisions in a quickly changing environment. People on the ground often post online messages that provide actionable information, but it can be difficult to find among all the noise. Can we monitor social media during a natural disaster or other crisis to inform first-responders? Can we discern the most vulnerable populations based on their attitudes before, during, and after the disaster?
During disasters such as hurricanes, first-responders need situational awareness to make the right decisions in a quickly changing environment. People on the ground often post online messages that provide actionable information, but it can be difficult to find among all the noise. Can we monitor social media during a natural disaster or other crisis to inform first-responders? Can we discern the most vulnerable populations based on their attitudes before, during, and after the disaster?
Publications
- Tweedr: Mining Twitter to Inform Disaster Response, ISCRAM 2014
- A demographic analysis of online sentiment during Hurricane Irene, HLT/NAACL 2012 Workshop
User Attribute Inference
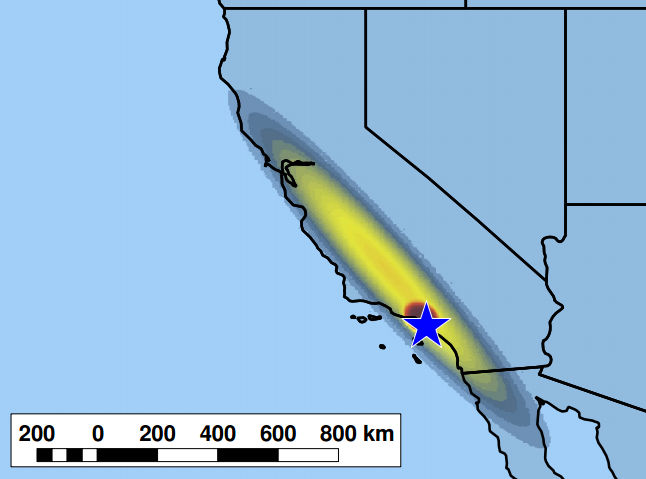 Using social media to inform health and disaster relief requires knowledge of user-level attributes, such as location, age, and gender, in order to produce accurate information. Can we infer such attributes from linguistic patterns of users? If so, what are the privacy implications of this technology?
Using social media to inform health and disaster relief requires knowledge of user-level attributes, such as location, age, and gender, in order to produce accurate information. Can we infer such attributes from linguistic patterns of users? If so, what are the privacy implications of this technology?
Publications
- When do Words Matter? Understanding the Impact of Lexical Choice on Audience Perception using Individual Treatment Effect Estimation, AAAI 2019
- Are Words Commensurate with Actions? Quantifying Commitment to a Cause from Online Public Messaging, ICDM 2017
- Using online social networks to measure consumers’ brand perception,
- Domain Adaptation for Learning from Label Proportions Using Self-Training, IJCAI 2016
- Predicting Twitter User Demographics using Distant Supervision from Website Traffic Data, JAIR
- Mining brand perceptions from Twitter social networks, Marketing Science
- Training a text classifier with a single word using Twitter Lists and domain adaptation, Social Network Analysis and Mining
- Finding truth in cause-related advertising: A lexical analysis of brands' health, environment, and social justice communications on Twitter, Journal of Values-Based Leadership
- Inferring latent attributes of Twitter users with label regularization, NAACL/HLT 2015
- Predicting the Demographics of Twitter Users from Website Traffic Data, AAAI 2015
- Using county demographics to infer attributes of Twitter users, ACL Joint Workshop on Social Dynamics and Personal Attributes in Social Media
- Inferring the Origin Locations of Tweets with Quantitative Confidence, CSCW 2014
- Too Neurotic, Not too Friendly: Structured Personality Classification on Textual Data, ICWSM 2013 Workshop
Information Extraction
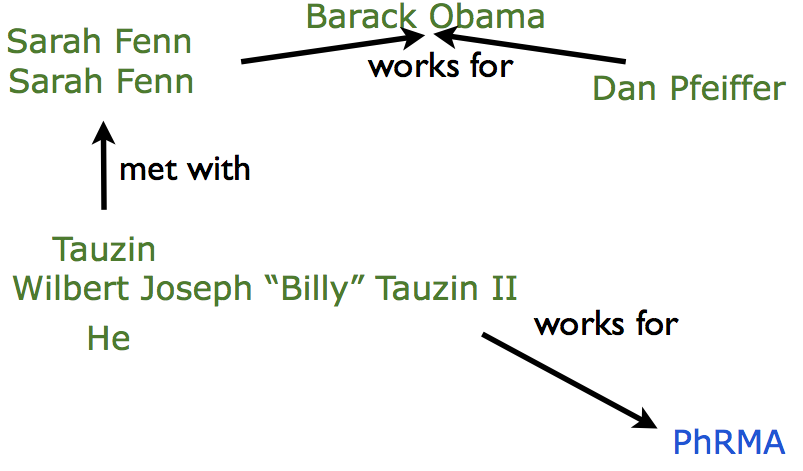 Most of the world’s information is intended to be read by humans, not computers. Information extraction transforms unstructured documents into structured representation, thereby allowing knowledge discovery applications to provide insights from large text collections. We explore statistical approaches to named-entity recognition, coreference resolution, and relation extraction.
Most of the world’s information is intended to be read by humans, not computers. Information extraction transforms unstructured documents into structured representation, thereby allowing knowledge discovery applications to provide insights from large text collections. We explore statistical approaches to named-entity recognition, coreference resolution, and relation extraction.
Publications
- An entity-based model for coreference resolution, ICDM 2009
- First-Order Probabilistic Models for Coreference Resolution, HLT/NAACL 2007
- Canonicalization of Database Records using Adaptive Similarity Measures, KDD 2007
- Author Disambiguation using Error-driven Machine Learning with a Ranking Loss Function, AAAI 2007 Workshop
- Learning field compatibilities to extract database records from unstructured text, EMNLP 2006
- Integrating probabilistic extraction models and data mining to discover relations and patterns in text, HLT/NAACL 2006
- Joint deduplication of multiple record types in relational data, CIKM 2005
- Extracting social networks and contact information from email and the Web, CEAS 2004
- Dependency tree kernels for relation extraction, ACL 2004
- Confidence estimation for information extraction, HLT 2004
Active Learning
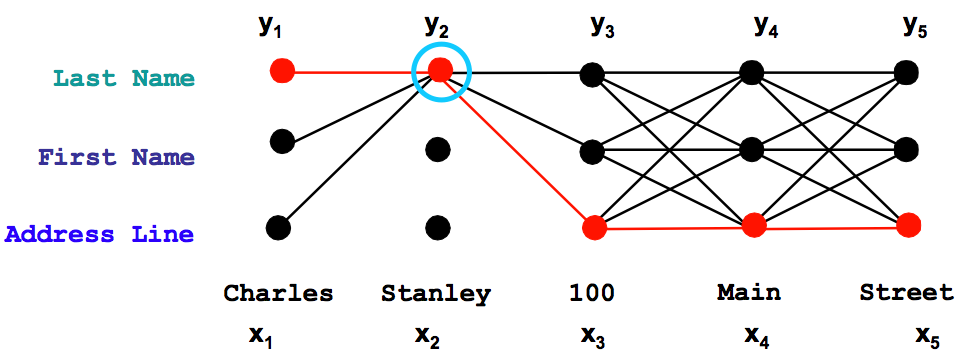 Most machine learning methods require costly human annotation efforts for training and validation. Can we more efficiently train machine learning models? We explore several interactive frameworks to improve the learning rate of machine learning algorithms, particularly for structured prediction problems.
Most machine learning methods require costly human annotation efforts for training and validation. Can we more efficiently train machine learning models? We explore several interactive frameworks to improve the learning rate of machine learning algorithms, particularly for structured prediction problems.
Publications
- Anytime Active Learning, AAAI 2014
- Towards Anytime Active Learning: Interrupting Experts to Reduce Annotation Costs, KDD 2013 Workshop
- Corrective Feedback and Persistent Learning for Information Extraction, Artificial Intelligence 2006
- Reducing labeling effort for structured prediction tasks, AAAI 2005
- Interactive information extraction with constrained conditional random fields, AAAI 2004
Scalable Machine Learning
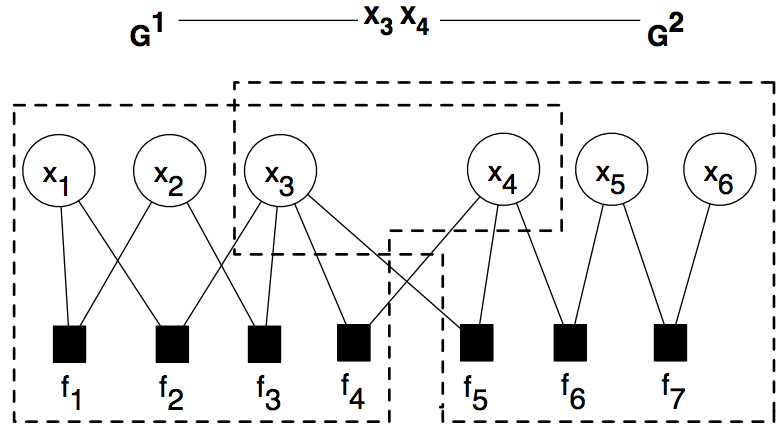 Most sophisticated structured prediction algorithms were not designed to run at Web scale. We explore accurate approximations that allow us to use rich data representations while scaling up to millions of variables.
Most sophisticated structured prediction algorithms were not designed to run at Web scale. We explore accurate approximations that allow us to use rich data representations while scaling up to millions of variables.
Publications
- SampleRank: Training factor graphs with atomic gradients, ICML 2011
- SampleRank: Learning preferences from atomic gradients, NIPS 2010 Workshop
- Learning and inference in weighted logic with application to natural language processing, PhD Thesis (UMass), 2008
- Sparse Message Passing Algorithms for Weighted Maximum Satisfiability, NESCAI 2007
- Tractable Learning and Inference with High-Order Representations, ICML 2006 Workshop
- Practical Markov logic containing first-order quantifiers with application to identity uncertainty, HLT/NAACL 2006 Workshop
- Learning clusterwise similarity with first-order features, NIPS 2005 Workshop